Le 15 juin 2006, le verbe to google fait son entrée dans le Oxford English Dictionary (Heyes et West, 2013; Oxford University Press, 2006). Cet événement de légitimation linguistique est à l’origine du projet artistique Google, Volume 1 (2013) des artistes anglais Félix Heyes et Benjamin West. Cette publication papier contient plus de 20 000 images qui remplacent chacun des mots du Oxford English Pocket Dictionary par le premier résultat d’une recherche d’images réalisée sur le moteur de recherche de Google. En n’utilisant que le premier résultat de recherche, ce projet montre l’image considérée la plus pertinente pour chaque mot. Il est présenté comme « la première réponse en image à tous les mots du dictionnaire » (Heyes et West). En 2014, on pouvait aussi lire sur la page de présentation de la recherche d’images de Google qu’il s’agit d’effectuer une recherche d’images afin d’« obten[ir] la représentation visuelle de [n]os termes de recherche1 ». Un projet similaire à celui de Heyes et West a été mis en ligne en 2014 sur Tumblr par Bertrand Gervais, professeur d’études littéraires à l'UQAM (Université du Québec à Montréal). Ce Dictionnaire visuel de Google (ou DVG) consiste en une série de captures d’écran des images formant les résultats de recherches Google effectuées avec différents termes. Le dictionnaire de Gervais apparaît plutôt comme un laboratoire sur la recherche d’images de Google, parce qu’il ne s’organise pas du tout à la façon d’un ouvrage de référence, même s’il est possible d’y effectuer également une recherche. Plusieurs séries de termes sont cherchés les uns à la suite des autres : des titres d’œuvres canoniques de l’histoire de l’art côtoient ceux du cinéma, des noms de couleurs, de figures de style, des noms de grands photographes ou de personnages de la mythologie grecque et plus récemment des requêtes ayant pour thème des évènements de l’actualité, comme les élections présidentielles américaines. Ces différentes séries se concluent parfois avec un court billet de l’auteur qui analyse les représentations que renvoient les termes. Les images de Gervais captent en moyenne quarante à cinquante résultats de recherche d’images et la publication indique les termes de la recherche. Cet éventail de résultats donne à voir une plus grande sélection de ce qui est considéré comme visuellement pertinent, en plus de faire apparaître la hiérarchisation des contenus que propose Google; le tout illustre une échelle de la pertinence.




Puisque Google est au cœur de notre expérience quotidienne du web et détermine notre façon d’y accéder et de se le représenter, il semble nécessaire de décrire comment s’articule cette pertinence dans notre rapport à l’information et aux images. Si les effets des algorithmes informatiques et statistiques sur la société sont de plus en plus étudiés dans le domaine de la sociologie et de la philosophie, ce vaste champ obscur est encore peu présent dans l’étude de la culture visuelle. Pour cet article, je propose donc de suivre les chemins que pointent les deux dictionnaires visuels de Google afin de mettre en lumière certains aspects de la notion de pertinence, qui organise les résultats de recherches d’images. En interrogeant les mécanismes du moteur de recherche, je chercherai à tracer quelques résonnances entre la conception de la pertinence chez Google et les notions d’autorité et de vérité qui semblent être retravaillées à différents niveaux en régime numérique. Il s’agira donc de comparer la fonction des ouvrages de référence de type dictionnaires avec Google, puis d’expliciter le travail des principaux algorithmes de classement qui agencent les résultats. Étant donné que les dictionnaires à l’étude sont avant tout visuels, ces dynamiques seront étudiées depuis le point de vue des images. Je propose en outre que l’adoption de ce point de vue dans l’étude de ce qui sous-tend la recherche web s’avère être une avenue critique féconde afin d’analyser ce qui façonne les réponses à nos requêtes sur Google. Il s’agira pour nous, par l’entremise des œuvres qui documentent les résultats de recherche et grâce à cette attention portée spécifiquement aux images, d’allier l’étude de l’aspect visuel de la recherche web à celle de la visibilité des objets en ligne. Une réflexion critique sur les logiques autoritaires, langagières et probabilistes des procédures de classement de l’information en ligne devient ainsi possible.
Des résultats pertinents
La définition de la pertinence ne fait pas consensus. Il convient tout de même d’en clarifier brièvement l’usage puisqu’il s’agit du principal critère agissant dans le façonnement des résultats présentés par les dictionnaires visuels. Étudiée en épistémologie, en sciences cognitives, en sciences de l’information ou en philosophie logique, la pertinence peut également relever de la compétence, de la justification ou même d’une pertinence politique, comprise en termes d’applicabilité sociale. Lorsqu’on l’aborde en recherche d’information (information retrieval), elle peut se référer à un phénomène qui permet de comprendre et d’apprendre — à tout le moins d’appréhender — ou encore de repérer une information, selon un besoin précis par un système ou par un utilisateur, un peu comme le recours à un annuaire ou un dictionnaire. Dans « La pertinence en sciences de l’information. Des modèles, une théorie? » (2008), Brigitte Simonnot compare les termes anglais relevance et pertinence selon leur étymologie. Relevance s’apparente au verbe « relever » et signifie à la fois « être du ressort de » et « mettre en relief », tandis que pertinence désigne plutôt le phénomène de « comprendre au moyen de quelque chose d’autre ». Cette dernière concerne donc l’adéquation d’un item (document, élément d’une liste, etc.) à une demande individuelle alors que la relevance s’applique à l’adéquation d’un objet informationnel à une demande plus générale qui peut être systématisée plus aisément. Dans le cas de Google, la définition la plus adéquate semble être celle de la pertinence en phase avec le domaine des sciences de l’information et la relevance de l’anglais. Autrement dit, dans la recherche en ligne qui sous-tend les dictionnaires à l’étude, la pertinence est une valeur accordée aux contenus proposés selon la requête par mot-clé et surtout par rapport à un ensemble d’objets similaires. Si les dictionnaires visuels avaient été produits autour de 1997, il est fort probable que les résultats de recherche d’images obtenus auraient été parsemés de contenus nous apparaissant aujourd’hui comme « non pertinents ». Avant Google, le principal critère de pertinence pour les moteurs de recherche, par exemple AltaVista, demeurait un calcul de « la densité de la présence du terme de recherche » sur la page (Cardon, 2013: 67). Les producteurs de contenus ont vite appris à tirer parti de ces algorithmes de correspondance lexicale en les manipulant à leur avantage. Depuis son lancement en 1998, Google est parvenu à mieux distinguer les contenus fiables des douteux, de même qu’à déterminer ce qui est plus approprié et utile pour l’usager parmi tout ce qui l’est « un peu », grâce à des algorithmes novateurs qui calculent la pertinence autrement que par simples correspondances de mots ou agrégations de clics. Ainsi, l’image du web que fournit Google sous forme de résultats pertinents est « nettoyée » et « pacifiée » afin de rendre la navigation en ligne harmonieuse malgré le chaos du cyberespace. En observant attentivement les images de Google, Volume 1 par exemple, on se rend compte de l’absence d’images pornographiques, même autour des mots du dictionnaire qui devraient normalement mener vers ce type d’images sans trop d’ambiguïté2. La dévalorisation systématique de la pornographie n’est qu’une des raisons qui poussent Dominique Cardon à affirmer que Google est une « machine morale » enfermant un système de valeurs (2013: 65). En excluant les « spams », le moteur veille à exclure les canulars, les sites miroirs, les références trompeuses, les propositions illégales, etc., c’est-à-dire ce qu’il considère inauthentique ou immoral. Cardon parle même d’une « police du web » (2013: 85), notamment lorsque des sanctions sont émises par Google. C’est probablement ce qui rattache le plus solidement Google à la notion d’autorité traditionnelle, lorsqu’elle est conçue comme une force normative3 et un pouvoir d’ordre et de décision, malgré toutes ses complexifications subséquentes.

Google a donc fait sa renommée grâce à cette « pertinence » des résultats qui se traduit en une correspondance plus satisfaisante entre des mots cherchés et la sélection effectuée sur les contenus, proposée sous forme de résultats. Larry Page (cité dans Hillis, Petit et Jarrett: 14), cofondateur de Google, explique clairement que le moteur aspire à comprendre exactement ce que vous cherchez afin de vous donner en retour exactement ce que vous voulez. Les captures de Gervais sont précisément une exploration des correspondances possibles entre les mots et les images. Certaines publications du Tumblr illustrent bien la manière dont la pertinence constitue, pour l’utilisateur, une adéquation entre les résultats et ce que nous avions en tête. En quête de représentations du vide, Gervais n’obtient que des photographies d’aspirateurs dans les résultats de sa recherche « vacuum ». Malgré les possibilités polysémiques, le ou les mots-clés de la requête sont le premier critère servant à définir la pertinence des résultats, puisqu’ils sont l’élément initiateur de la recherche. L’utilisateur-chercheur en est l’évaluateur le plus évident. Comme elle est ce qui résulte, la pertinence est une question de cohérence pour l’internaute, laquelle se dessine surtout lors de l’étape de représentation incarnée par l’affichage de résultats.
Indexer et classer d’abord
Cependant, pour que Google puisse renvoyer une liste de résultats pertinents, non seulement faut-il que le moteur comprenne ce que cherche l’utilisateur, mais il lui faut également comprendre les contenus et le poids des pages web, en allant bien au-delà de la correspondance entre mots-clés. La pertinence intervient donc aussi en amont des résultats, en définissant l’autorité des sources. Pour ce faire, un très grand nombre de critères, de données et de calculs sont mis en œuvre avant la moindre requête. Google doit d’abord indexer le web en envoyant des robots qui parcourent la toile en sautant de lien en lien. Les pages de sites sont indexées, c’est-à-dire copiées dans l’index-archive4 des centres de données afin d’être décortiquées, soupesées et éventuellement classées selon leur importance en vue de fournir des résultats pertinents en réponse aux requêtes. Lorsque l’internaute soumet un mot-clé à Google, le moteur ne cherche pas dans le web en temps réel, mais dans son index morcelé, stabilisé et hiérarchisé.
Les résultats colligés dans les dictionnaires d’images représentent les plus hauts niveaux de légitimation que permettent ces mots-clés dans le web. Google ne dévoile jamais clairement tout ce qui entre en jeu dans ses algorithmes de classement, mais les spécialistes du référencement web en sont venus à se faire une bonne idée de ce qui prime sur le reste. Les mots-clés doivent apparaître dans la balise de titre, les liens entrants doivent être de « qualité », le contenu doit être original, à quoi s’ajoutent des dizaines d’autres critères et des centaines de petites variantes sans cesse réajustées (SEO Factors). Les sites qui souhaitent être visibles dans le web doivent également se plier aux exigences d’indexation de l’engin de recherche pour éviter d’être pénalisés. Non seulement les processus établis en fonction des critères de pertinence façonnent l’accès aux contenus par les internautes en ordonnant leur visibilité, elle façonne également leur production.
Référence : enjeux d’autorité et de pertinence
La notion de pertinence chez Google semble donc être étroitement liée à celle d’autorité. Le moteur de recherche définit, incarne et complexifie l’autorité de différentes façons. Il « fait autorité » en agissant comme un incontournable à la fois pour les internautes, pour les producteurs de contenus et pour les annonceurs publicitaires. Il décide de ce qui doit être visible dans le web en classant les pages selon sa conception de l’autorité des sources. Il fonctionne de plus en plus en mode prédictif, se nourrissant des traces laissées par les usages antérieurs afin de tracer des profils, de prédire et de proposer ce qui pourrait être pertinent. Cette grande pertinence des résultats est ce qui fait de Google la référence principale pour s’orienter en ligne : il nous réfère à ce qui a été préalablement défini (et continuellement redéfini) comme pertinent.
La question de l’autorité est souvent imbriquée à celle de la référence. C’est la première direction qu’indiquent les projets de Heyes et West ou de Gervais en empruntant l’intitulé de dictionnaires. Celui-ci n’est pas anodin, dans la mesure où il s’agit de qualifier ainsi leurs assemblages d’images-résultats. Un dictionnaire est un ouvrage présentant ce qui est admis dans la langue et servant également à en normaliser la forme, les usages. La fonction référentielle de Google peut effectivement s’apparenter à l’usage d’un dictionnaire traditionnel lorsqu’il sert à confirmer une information, même s’il occupe surtout le rôle de relais vers des références externes. Il est nécessaire de souligner ce premier rôle de médiation active que joue Google dans la référence, puisque son usage est de plus en plus intériorisé et naturalisé. Le moteur de recherche couvre beaucoup plus que le seul sujet du langage en organisant une grande partie des contenus web, voire en en normalisant la forme et les usages, comme le fait le dictionnaire avec la langue. Néanmoins, la fonction recherche de Google demeure fortement dépendante du langage puisque le point de départ de la plupart des requêtes est le mot-clé. Peter Linsley, l’un des responsables de Google Images, signale par ailleurs qu’un des usages de la recherche d’images s’apparente à celui d’un dictionnaire (2009) : plusieurs utilisateurs soumettent un mot inconnu à la recherche d’images afin de voir immédiatement de quoi il s’agit plutôt que de lire une définition écrite. La vocation exclusivement linguistique et l’ordonnancement alphabétique du dictionnaire traditionnel sont subvertis par les projets de dictionnaires visuels, avec lesquels il devient impossible de vérifier : ni la langue, ni les images. C’est leur mise en relation par l’entremise de Google qui peut être observée, c’est-à-dire que la fonction de référence disparaît au profit d’une observation de type laboratoire qui souligne cette importance des mots dans la recherche en ligne.
En s’attardant sur toute la connaissance plutôt que sur la langue, le format encyclopédique se rapproche peut-être davantage des prétentions googliennes cherchant à rassembler toute l’information du monde5. L’encyclopédie cherche à résumer un nombre important de choses à partir de faits. Google ne résume pas, il ne produit pas (ou peu) de textes de référence. Il vise l’exhaustivité par la collecte, pour ensuite organiser, filtrer, pointer et offrir une représentation de ce qui est important dans le web.
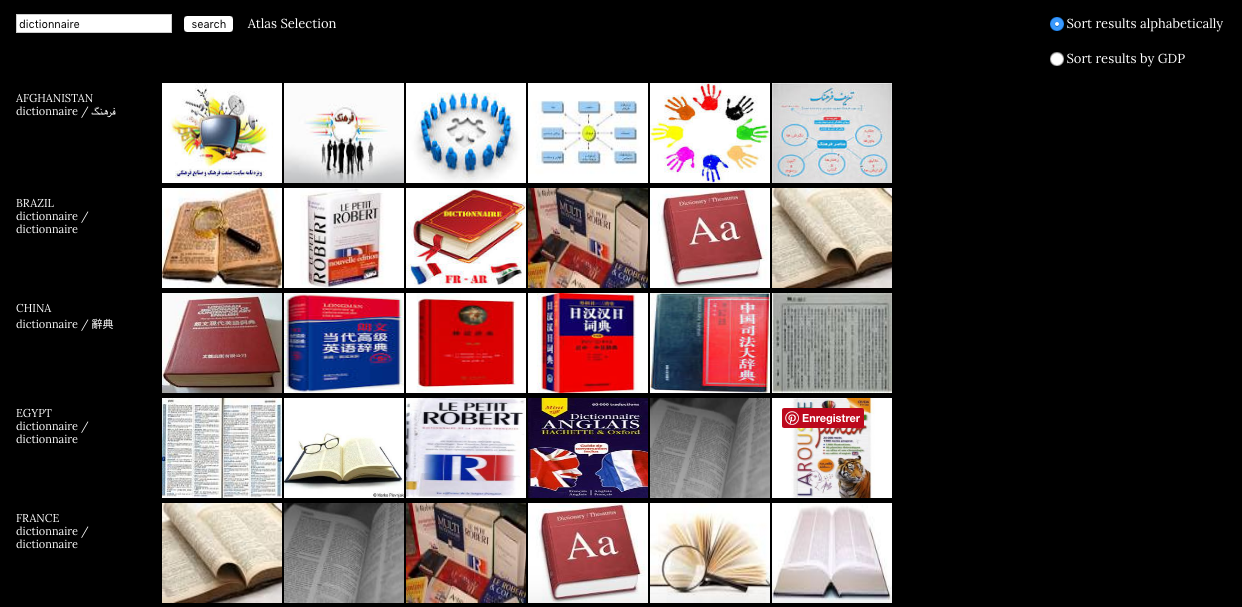
Il est également opportun de mentionner le projet imageatlas.org (2012) de Taryn Simon et Aaron Swartz puisqu’il reprend le nom d’un autre ouvrage de référence. Dans ce projet en ligne qui interroge l’universalité et la neutralité des engins de recherche web, la personnalisation géographique est exacerbée à travers le format de l’atlas, lequel traditionnellement rassemble des cartes géographiques. L’atlas de Simon et Swartz permet de voir comment diffèrent les résultats de recherche d’images dans 57 pays. Cela met en avant la personnalisation croissante des résultats de recherche et le fait que les représentations visuelles associées à certains mots varient grandement selon la provenance de la requête. La pertinence sur Google est effectivement de plus en plus territorialisée. De même, les choix qu’opèrent les concepteurs d’un atlas sur les façons de représenter le monde sont particulièrement intéressants à considérer lorsqu’on souhaite s’attarder sur les façons de représenter ce « territoire » qu’est le web à travers la notion de pertinence de Google, qui nous aide à nous « orienter ». Parallèlement, l’atlas géographique fait référence à un imaginaire cartographique du réseau et de la toile qui va de pair avec une conception relationnelle de la pertinence telle qu’encodée dans les algorithmes.
Autorité algorithmique
Pour Cardon, le passage d’un filtre a priori traditionnel à une organisation a posteriori de l’information par le moteur de recherche web nous a fait passer d’une forme d’« éditorialisation » des contenus vers une « autorité algorithmique » (2010: 194). Les algorithmes de Google sont une forme d’autorité et la définissent. Même s’il ne représente qu’une portion de l’ensemble des calculs effectués afin d’opérer le classement des résultats, le PageRankTM est le célèbre algorithme de Google concevant le web de façon relationnelle. Il détermine l’une des facettes de ce qui se trame sous la pertinence, grâce à un calcul de l’autorité fondé largement sur la notoriété des pages web indexées. En somme, le niveau d’autorité d’un site est déterminé en fonction du nombre de liens qui pointent vers lui. Le PageRank émerge en grande partie de la scientométrie, c’est-à-dire de « l’ambition du Science Citation Index [d’Eugene Garfield] de représenter la science par le tissu de ses citations » (Cardon, 2013: 68). C’est la première fois qu’un moteur de recherche s’appuie sur la structure hyperliée qui est le propre du web, afin de penser la pertinence au-delà de la correspondance sémantique (Cardon, 2013: 66). Larry Page affirme : « Les liens hypertextes […] encodent une somme considérable de jugements humains latents et nous prétendons que c’est exactement ce type de jugement qui est requis pour formuler la notion d’autorité » (cité dans Cardon, 2013: 71). L’hyperlien s’est effectivement avéré l’une des valeurs de calcul les plus efficaces afin d’obtenir l’information la plus probablement pertinente dans les résultats de recherche.
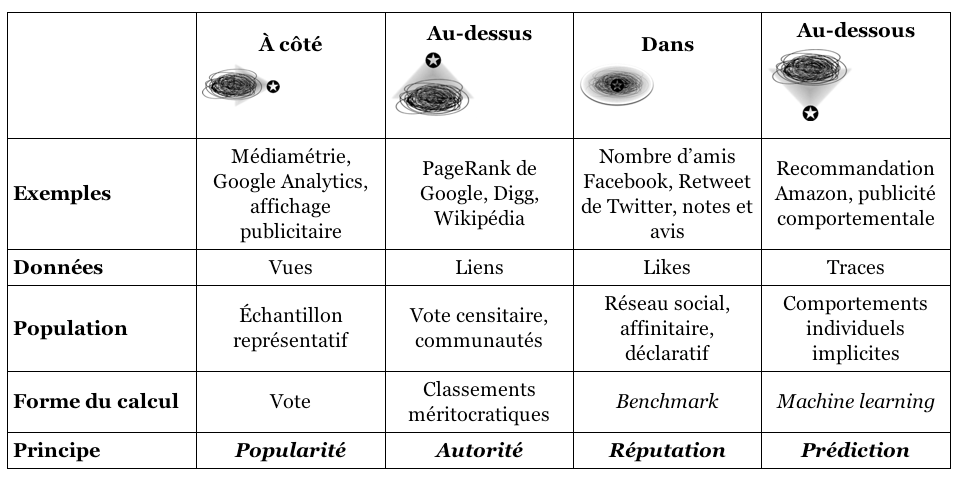
Les « votes » sur le mérite que produisent les hyperliens ne sont toutefois pas égaux6. En fait, Google cherche à atteindre une méritocratie qui se fonde plus sur l’autorité que la popularité, même s’il peut être difficile de départager les deux. Cela découle probablement du fait que la définition d’autorité fait augmenter la visibilité et ainsi la popularité. Dans À quoi rêvent les algorithmes? Nos vies à l’heure des big data (2015), Cardon les différencie approximativement comme suit : l’autorité est le nombre de liens entrants et la popularité, le nombre de clics des internautes7. En théorie, l’autorité devrait être méritée et non fabriquée. Cardon ajoute cependant à ce propos que lorsque les liens sont effectués « en fonction du méta-coordinateur qui les agrège, la pertinence épistémique du résultat en sera profondément altérée » (2013: 79). Difficile alors de réduire la notion de pertinence de Google à une simple agrégation des préférences des internautes. Il reste que cette brève description du PageRank nous permet d’entrevoir comment la logique des images tend à subvertir cette conception de la pertinence. On peut effectivement se demander comment les images qui forment les dictionnaires visuels peuvent être jugées plus pertinentes que d’autres quand elles ne sont pas hyperliées entre elles. Cela semble être un point aveugle de la conceptualisation de l’autorité de l’information.
Afin de clarifier mieux encore le fonctionnement « autoritaire » de Google, on peut également convoquer les travaux d’Antoinette Rouvroy, qui tente de définir les caractéristiques et les effets d’une « gouvernementalité algorithmique », différente de la « normativité juridico-discursive » (Rouvroy et Berns). La gouvernementalité algorithmique est définie comme « opérant par configuration anticipative des possibles plutôt que par réglementation des conduites, et ne s’adressant aux individus que par voie d’alertes provoquant des réflexes plutôt qu’en s’appuyant sur leurs capacités d’entendement et de volonté » (Rouvroy, 2012: n.p.). En rendant difficile la désobéissance devant une norme et des règles qui ne sont plus explicites, les algorithmes complexifient grandement la notion d’autorité, traditionnellement plus juridique ou discursive. Sans qu’il faille détailler les effets d’une normativité intériorisée par la « personnalisation générique » des résultats de recherche (Hillis, Petit et Jarrett), on comprend l’ampleur du phénomène que représente la notion de pertinence chez Google.
De la vérité à la pertinence
Les caractéristiques de ce mode de gouvernement permettent également d’examiner les articulations possibles entre la notion de vérité et la pertinence, notamment avec les échanges entre Rouvroy et Bernard Stiegler (2015). Pour Rouvroy, il ne s’agit pas d’un nouveau régime de vérité, mais d’une mise en crise de ces régimes. Ce type de « vérité numérique » que j’associe ici en grande partie à la pertinence semble effectivement fonctionner différemment des régimes de vérité théorisés par Michel Foucault (1994 [1976]: 114). Même s’ils expriment bien les dynamiques de savoir et de pouvoir qui sont également à l’œuvre dans la pertinence de Google, ces régimes supposent une subjectivation (Deckeyser) qui s’estomperait en ligne (Rouvroy, 2012; Rouvroy et Stiegler, 2015)8. Rouvroy admet que la vérité « algorithmique » peut opérer de façon similaire lorsqu’il s’agit de considérer les « processus à travers lesquels s’établit ce que l’on tient pour vrai », mais précise que « la notion de processus ici est fortement ramassée sur une actualité pure » (2015: 125-126). Dans ce régime des algorithmes, la réalité se replie sur la vérité, « une réalité qui se prétend le monde9 » (Rouvroy, 2015: 118). En cherchant à neutraliser les effets de l’incertitude, cet « accolement » en vient même à faire perdre la possibilité de la critique (Rouvroy 2015: 115)10.
La question de la vérité est donc dépendante du pouvoir d’autorité et inversement. Comme Foucault le précise, « la “vérité” est liée circulairement à des systèmes de pouvoir qui la produisent et la soutiennent, et à des effets de pouvoir qu’elle induit et qui la reconduisent » (1994 [1976]: 114). De même, la notion de la vérité est intimement liée à « la compréhension de l’expérience interrogative » (Deckeyser: 10) et les projets de dictionnaires découlent précisément de ce « nouveau » type d’expérience interrogative qu’est la recherche en ligne. Si la « pertinence » des réponses de Google à nos questions prend le dessus sur leur « vérité », ces deux termes semblent cependant présenter maintes similitudes, maints recoupements. Lorsque Roger-Pol Droit aborde la notion de vérité dans « Authenticité générale, authenticité juridique », il fait écho à la définition de la pertinence : « est vraie une idée qui, dans mon esprit, correspond exactement à la chose qui se trouve en dehors de mon esprit » (224). Certes, la « vérité » a plusieurs significations philosophiques, mais elle est souvent comprise comme une correspondance entre la connaissance et le réel. Même si la pertinence googlienne ne relève pas de ladite « vérité » dans sa définition commune d’objectivité scientifique (encore que la survalorisation des calculs mathématiques vise effectivement une objectivité absolue), les principes d’adéquation et de pouvoir qui la sous-tendent apparaissent utiles pour interroger la recherche en ligne qui anime les projets de dictionnaires visuels. La pertinence s’allie certainement à une théorie « correspondandiste » de la vérité, mais d’autres théories comme celles « de la cohérence », « de la révélation » ou d’une vérité dite « pragmatiste-utilitariste » (Volpe et Zygulski) résonnent également avec les différents aspects de la pertinence que nous abordons dans cet article. Les auteurs de Google and the Culture of Search (Hillis, Petit et Jarrett: 74-75) proposent aussi un phénomène logique intéressant pour réfléchir la pertinence et la vérité : la truthiness. Formulé par l’humoriste Stephen Colbert en 2005, il s’agit d’un phénomène de croyance intuitive en un « faux vrai » (qui peut aussi bien être vrai) : la proposition nous semble vraie donc elle l’est. La pertinence est aussi une formulation plus attrayante pour l’internaute qui préfère avoir l’impression d’être libre de choisir plutôt que de se faire imposer des idées préalablement établies comme « vraies ». En outre, ce qu’on voit du web à travers les résultats de recherche de Google comme ceux qui sont présentés dans les projets de dictionnaires incarne ce qui nous semble être le web. Les dictionnaires visuels de Google ont donc tout à voir non seulement avec les images, mais également avec le visible.
Le dictionnaire de Heyes et West trace plus explicitement un parallèle entre l’autorité d’un dictionnaire et celle de Google, non seulement dans la forme, mais aussi parce qu’il utilise toujours le premier résultat. Le filtrage des résultats de recherche d’images est encore plus drastique que dans une liste et semble plutôt incarner la fascinante option « J’ai de la chance » qui mène l’utilisateur directement au premier résultat, en escamotant la traditionnelle étape de la liste et en proposant ainsi le jeu d’un pari sur la pertinence instantanée. Ce n’est cependant pas de cette façon que la recherche s’éprouve au quotidien et surtout pas du côté des images. Comme Linsley le souligne à l’attention des webmestres, le « paradigme » de la recherche d’images n’est pas celui du premier résultat parfaitement pertinent (2009). Les utilisateurs parcourent rapidement du regard l’ensemble des premiers résultats et même ceux des pages suivantes afin de trouver ce qui leur convient, contrairement aux résultats textuels où le classement dans les premiers rangs est crucial. En dépit des dynamiques relevant de l’autorité dans la conception googlienne de la pertinence, le projet plus exploratoire de Gervais illustre le sentiment de liberté que peut procurer la recherche avec Google. Ippolita écrit d’ailleurs que les barres blanches de recherche « sont des bols d’air, des fenêtres privilégiées, grandes ouvertes sur le monde fascinant de la Toile » (8). Se dessinent alors les paradoxes de la gouvernementalité algorithmique. Lorsque nous effectuons une recherche, nous avons des dizaines (voire de milliers, si nous parcourons réellement toutes les pages de résultats, ce qui demeure peu probable) de choix parmi les résultats pour sélectionner ce qui nous convient. C’est précisément ce sentiment qui permet aux mécanismes de gouvernement (ou de gouvernance?) de se mettre en place11. La pertinence semble se constituer d’un effet de vérité ou de « truthiness » prenant la forme d’un mode de véridiction individuel qui s’arrime bien à un désir de liberté, ancré dans les espoirs libertaires ou antiétatiques qui teintent l’histoire d’Internet. Dans ses échanges avec Stiegler, Rouvroy ajoute : « On ne s’est peut-être jamais senti aussi libre que dans un régime de gouvernementalité algorithmique. » (2015: 126.) Après avoir décrit quelques enjeux d’autorité et de vérité de la pertinence chez Google, il convient donc de préciser comment cela peut fonctionner à partir d’un désir paradoxalement antiautoritaire des internautes, généralement très rébarbatifs à toute imposition explicite d’une autorité ou d’une vérité. Ainsi, les résultats ne font que proposer des options parmi lesquelles on se sent libres de choisir, même si elles sont grandement filtrées. C’est bien de cela dont parle Foucault lorsqu’il soutient que la gouvernementalité cherche à convaincre plutôt qu’à contraindre (Lascoumes). Il s’agit de « gouverner en paraissant ne pas gouverner », en gouvernant à partir du réel plutôt qu’en gouvernant le réel (Berns: 386-389).
Du visible aux images

De même, en ordonnant la visibilité des images selon la pertinence des sites et de leurs contenus, Google Images façonne imperceptiblement une partie de notre culture visuelle en fonction de ses propres paradigmes. La recherche d’images et les projets de dictionnaires visuels de Google exposent le primat du langage qui régit la pertinence pour Google. L’une des définitions de la pertinence selon le Larousse (s.d.) la présente d’ailleurs comme « un élément linguistique qui joue un rôle à l’intérieur d’un système, d’une structure12 ». Malgré l’importance accordée aux hyperliens dans le calcul de la pertinence plutôt qu’à la correspondance lexicale, de même qu’aux plus récents développements de la recherche par image, les mots sont encore au centre de notre rapport à l’information et aux images en ligne. Le dictionnaire visuel de Heyes et West montre comment les images ne peuvent pas être comprises comme le langage puisque l’ordre alphabétique n’est pas un mode de classement valable pour retrouver des images. La publication retire la fonction de référence du dictionnaire en lui ôtant son objet principal, la langue, et en ne conservant que sa structure organisationnelle de façon à montrer son inopérabilité dans le régime visuel. Comme pour les pages web, la pertinence des résultats de recherche d’images est une question de probabilité qui se fonde d’abord sur des calculs et des mots. En dehors des signaux rassemblés à propos du site publiant l’image (et du chercheur), la plupart du temps, tout ce qui importe sont les mots du texte présents sur la page, la légende, le nom du fichier et le « alt text » : une description textuelle succincte considérée équivalente à l’image (Cutts, 2007). Le robot-indexeur « Googlebot-Image » ne voit pas véritablement et encore moins systématiquement le contenu des images. En fait, le classement des résultats est quasi-aveugle : certaines images pourraient aussi bien être vides que cela ne changerait pas la prééminence qui leur est accordée dans les résultats13. Non seulement les images ne sont pas hyperliées entre elles comme les sites, mais leur circulation et leur reproduction n’entrent que bien indirectement en compte dans les calculs. Une image pourrait être reproduite sur des millions de sites ne contenant que des images, cela n’affecterait pas l’évaluation de sa pertinence14. Néanmoins, pour quelques requêtes d’images très populaires, comme « La Joconde » du Dictionnaire visuel de Google, le moteur de recherche utilise des algorithmes qui reprennent les principes du « VisualRank », un prototype présenté au public en 2008, afin de ne présenter qu’une seule version de la même image dans ses résultats : l’image dite « canonique » parmi les « doublons » (Jing et Baluja; Linsley). Il est particulièrement fascinant de penser que cet algorithme a pour objectif de déceler « l’autorité » visuelle afin de renvoyer l’image la plus pertinente possible (Jing et Baluja). Cela s’effectue à l’aide de graphes rassemblant et analysant les images similaires dans le but de cerner une certaine centralité visuelle au sein d’un groupe d’images semblables. Les similarités sont considérées un peu comme des « hyperliens visuels probabilistes15 » (Jing et Baluja: 1879). Certainement mis en application et raffiné depuis la publication de l’article de Jing et Baluja, qui proposait la mise en place de cet algorithme, le VisualRank de Google serait « le PageRank appliqué à la recherche d’images à grande échelle16 » (Jing et Baluja: 1877). Dans cette logique autoritaire et inductive qui tend à prioriser une certaine unicité de l’image, l’utilisation d’images génériques et très reproduites, provenant de banques d’images par exemple, pourrait éventuellement être considérée comme un défaut dans l’évaluation de la qualité d’un site, quoique ce ne soit pas le cas pour l'instant (Cutts, cité par Slegg, 2013). Il semble donc que ce moteur de recherche soit tout de même apte à détecter les indices de ce qui se trouve dans l’image indexée (Cutts), encore avec pour objectif de cerner l’autorité; il demeure cependant difficile d’employer ces calculs pour l’ordonnancement d’une pertinence visuelle conséquente (Jing et Baluja). Le VisualRank vise surtout à éviter les redondances et à diminuer le « bruit » de la non-pertinence. Considérant les recherches actuelles en intelligence artificielle et en reconnaissance d’images, il semble que les capacités de la vision automatisée soient encore très peu utilisées dans la recherche d’images par mot-clés (Anonmye, 2012)17. Le VisualRank semble être utilisé surtout dans le cas de très grandes quantités d’images similaires et de requêtes déjà populaires (Jing et Baluja: 1885). Si l’iconicité ou « l’homogénéité du concept visuel18 » (Jing et Baluja) des résultats-images de « La Joconde » de Gervais se soumet probablement à cette analyse visuelle par graphes, ce qui résulte de la requête « Invisible » n’est vraisemblablement pas passé par un tel filtre. Le VisualRank a besoin de très grandes quantités d’images similaires pour fonctionner puisqu’il s’agit précisément de cerner les similitudes pour une même requête et non d’identifier les motifs (Jing et Baluja: 1888). Dans ces conditions, l’usage de mots est encore grandement nécessaire. Google rappelle d’ailleurs sans cesse aux webmestres qu’une page contenant plus de texte pour une même image est habituellement mieux classée (Anonyme, 2012).

Les réflexions de Gervais à propos du visible chez Google Images sont également symptomatiques de la dominante langagière dans notre conception du web. Après avoir effectué une série de captures d’écrans de résultats de recherche comprenant les mot-clés « invisible », « non-être », « impalpable », et d’autres termes analogues, il publie un article dans lequel il affirme que « plus rien n’échappe au visible » et que « tout se donne à voir » (2011). Ce serait « la grande leçon des moteurs de recherche ». Il ajoute : « Nous sommes […] dans un régime de la visibilité absolue. Tout est image. Il n’y a plus de mystère. » Cette conclusion apparaît bien étrange du point de vue des études sur la culture visuelle et sur le web. Bien sûr, la quasi-totalité des mots du dictionnaire obtiennent des résultats sur Google, peu importe le niveau de tangibilité auquel il se réfère, puisque la langue est un des principaux organisateurs de la recherche en ligne, en plus d’être la marchandise que vend Google (pensons aux fameux AdWords). Il est parfaitement logique que des images soient associées à ces mots. Or, le monde (en ligne et hors ligne) ne se résume pas au langage19. Malgré l’abondance d’images accessibles dans le web, tout n’est certainement pas visible. Ce n’est pas le visible qui est couvert par les images disponibles en ligne, c’est la langue qui est recouverte par les images qui débordent d’ailleurs toujours les mots, tant du point de vue du sens que la quantité. En étudiant la photographie, par exemple, le rapport à ce qui échappe au visible et ce que les photographies ne montrent pas est souvent mis en avant. Ce qui est occulté par un corpus de photographies d’un événement est souvent révélateur. L’étude des images nous apprend toute l’importance de l’invisibilité face à l’hypervisibilité. Malgré le sentiment d’infinitude que procurent les milliers de résultats de recherche présentés, Google Images ne permet pas de vision panoptique. Il est bien loin d’accorder un accès universel à tout le visible par sa recherche d’images, encore davantage de rendre toute chose visible. La question de la visibilité est également une préoccupation constante pour quiconque s’intéresse aux dynamiques du web. Dans l’accès à l’information en ligne, ce qui est visible est ce qui importe. À cet égard, il est primordial de rappeler ce qu’observait récemment Cardon (2016) : Google effectue une hiérarchisation « extrêmement violente » qui transforme ce qui est visible dans le web; jusqu’à 95 % des usagers sont dirigés vers 0,03 % des contenus en ligne.
C’est pourquoi il est essentiel de se demander comment préserver la diversité et l’activité délibérative nécessaire à la légitimation de l’information. Les difficultés d’automatisation que posent la polysémie et l’indétermination des images, ou encore leur logique possiblement « non prédicative » semblent, selon Gottfried Boehm, fécondes à ce propos : « [L’image] n’est pas formée sur le modèle de la proposition ou d’autres formes langagières. Elle n’est pas parlée mais réalisée en étant perçue. » On peut alors postuler que se pencher sur la recherche d’images permet d’amorcer une exploration du potentiel de l’indéterminé qui nuance les différents déterminismes régissant notre rapport aux contenus du web et ainsi remettre en question une gestion axée sur des mots, sur des corrélations mathématiques et sur une logique inductive. Ce faisant, l’information se voit conférer une forme de vérité par probabilité plutôt que par opposition à la fausseté, probabilisme qui caractérise également la gouvernementalité algorithmique20. Cela s’apparente à l’effet de vérité de la « truthiness » et de la notion de pertinence des résultats, laquelle vise à définir ce qui est le plus probablement pertinent, adéquat ou vrai pour l’internaute. En philosophie de la science, Karl Popper a critiqué la production de savoir par logique inductive et proposé plutôt l’indéterminisme21. Il s’agit d’un indéterminisme qui se rapproche de celui des images selon Boehm et du « virtuel » que Rouvroy (2015: 124) identifie comme « dimension de possibilités » et oppose à l’actuel (plutôt qu’au réel). Elle propose ce « virtuel » afin « de ne plus opposer déterminisme et liberté » (Rouvroy, 2015: 117). L’examen attentif des dictionnaires visuels et du fonctionnement des recherches sur Google fait apparaître le domaine des images comme un lieu fort en incertitudes22. Malgré une apparente docilité aux mots et aux calculs, les images représentent des failles pouvant aller à l’encontre de la « managérialisation » (Rouvroy, 2012) du web et de ses usage(r)s que permettent les collectes et l’analyse de données numériques de masse. Les images semblent pouvoir occuper une portion de cet « excès du possible sur le probable23 » dont parle Rouvroy (2015). C’est ici que se dessine la possibilité de la critique. Les projets qui reprennent des résultats de recherche sur Google offrent une représentation qui ouvre la voie à une réflexion dans l’après-coup. Documents ou témoignages visuels de la recherche, les captures d’écrans de Gervais, à l’instar des images publiées par Heyes et West, fonctionnent comme des photographies de cet aspect visuel de la recherche en ligne qui permettent de la réfléchir.
Conclusion
L’étude des enjeux sous-jacents aux projets de dictionnaires visuels de Google par Heyes et West et par Gervais ouvre la voie à une critique de différents aspects de la notion de pertinence chez Google. L’association entre pertinence et autorité qui a été explorée dans cet article conduit à une compréhension de la pertinence googlienne comme un ensemble de procédures de classement qui découlent de critères moraux, de la structure hyperliée et langagière du web, mais aussi des calculs de probabilité. Il est de plus en plus évident qu’il s’agit d’une pertinence par probabilité dans laquelle l’autorité et la vérité dépendent aussi en grande partie d’une expertise calculatoire et d’approximations. En découle une objectivité instrumentale, voire scientiste, qui vise l’efficacité et l’utilité (Cardon, 2016). En s’attardant aux dictionnaires visuels de Google, aux résultats qu’ils présentent et aux dynamiques qui organisent ces représentations, on peut aussi souligner le déterminisme linguistique de la recherche. Google Images est d’ailleurs très peu étudié, contrairement à Google Books par exemple, ce qui démontre une fois de plus la préséance du textuel sur le visuel. La pertinence de Google détermine non seulement l’accessibilité aux contenus et leur visibilité, mais également le visible dans la portion images de la recherche. Grâce à cette attention portée aux images, on voit qu’elles s’avèrent difficiles, voire impossibles à soumettre à la logique de l’hyperlien et de la langue. Pourtant, le web se construit de plus en plus d’images. Puisque le cyberespace est chevillé à la plupart des aspects de notre quotidien et régi par des machines qui produisent des modèles prédictifs pour nous aider à opérer des choix sur le monde, tenter de comprendre les logiques qui les animent semble nécessaire. La boîte noire de la recherche d’images de Google n’est manifestement pas encore assez ouverte et mes recherches se poursuivent afin de tenter d’éclaircir ces mécanismes qui innovent sans cesse. Nous concentrer sur la dimension iconique du web afin d’observer celui-ci et mieux comprendre cette entité qui nous oriente à travers le dédale iconographique nous permet de nous approprier le point de vue privilégié des images, lesquelles sont à la fois partout et indisciplinées au sein des structures hyperliées et langagières du web fédéré par des moteurs de recherche. Cela permet de s’atteler à cette portion encore un peu rebelle ou à une source de récalcitrance, d’où pourraient émerger des possibles non répertoriés de ces assemblages sociotechniques complexes — du moins jusqu’à ce que l’intelligence artificielle en cours de développement chez Google parvienne à mieux percevoir les images et leur logique, ce qui se trame déjà chez Google Photos.
- 1. La citation provient de la page « Google recherche d’images » de la Search Help Console de Google, mais elle date d’une consultation antérieure, plus précisément du 4 janvier 2014. La phrase n’y est plus.
- 2. Les images les plus explicites de l’ouvrage sont des photographies à caractère médical, illustrant des problèmes de santé.
- 3. À propos des effets normatifs des algorithmes, voir l’article de Rouvroy et Berns.
- 4. Nous lions ces mots par un trait d’union puisque leurs fonctions respectives se retrouvent particulièrement emboîtées dans les centres de données de Google.
- 5. La version originale anglaise de la mission de Google est la suivante : « Google’s mission is to organize the world’s information and make it universally accessible and useful. » (« About - Company ».) [Je souligne.]
- 6. « Le PageRank considère que les internautes publiants sont égaux, mais que leurs pages ne le sont pas et il fait de cette séparation entre la personne et la page une manière de préserver le principe d’autorité lorsque le droit de publier est ouvert à tous. » (Cardon, 2013: 74-75.)
- 7. Cardon souligne aussi que la notion d’autorité chez Google est en crise devant différents calculs : la popularité, la réputation et l’efficacité prédictive des algorithmes autoapprenants de la collecte de données (2015: 91).
- 8. Rouvroy va très loin dans sa description de la désubjectivation qui a cours en ligne : « Et là aussi on contourne la subjectivité, puisqu’on ne fait pas appel à vos capacités d’entendement et de volonté pour vous gouverner, ou faire en sorte que vous passiez à l’acte d’achat, ou, au contraire, que vous n’imaginiez même pas désobéir à une règle. Ce n’est plus en vous menaçant ou en vous incitant, c’est tout simplement en vous envoyant des signaux qui provoquent du réflexe, donc des stimuli et des réflexes. Il n’y a plus de sujet, en fait. Ce n’est pas seulement qu’il n’y a plus de subjectivité, c’est que la notion de sujet est elle-même complètement évacuée grâce à cette collecte de données infra-individuelle, recomposée à un niveau supra-individuel sous forme de profil. Vous n’apparaissez plus jamais. » (2015: 122.)
- 9. « Dès lors qu’il “suffit” de faire tourner des algorithmes sur des quantités massives de données pour en faire surgir comme par magie des hypothèses à propos du monde, lesquelles ne vont pas nécessairement être vérifiées, mais seront opérationnelles, on a effectivement l’impression d’avoir décroché le Graal, d’avoir atteint l’idée d’une vérité qui ne doit plus, pour s’imposer, passer par aucune épreuve, aucune enquête, aucun examen, et qui, pour surgir, ne dépend plus d’aucun événement. Dans cette mesure, on s’écarte, me semble-t-il, à la fois de la notion de régime de vérité chez Foucault et du lien qu’Alain Badiou faisait entre “événement” et “vérité”. » (Rouvroy, 2015: 118-119.)
- 10. « Ce qu’on peut percevoir est une recherche d’objectivité absolue, une recherche pour coller au plus près du réel, qui est en fait une recherche de sécurité se traduisant par une recherche de certitude. C’est une trajectoire assez particulière : recherche d’objectivité et de sécurité qui se traduit par une recherche, je ne dirais pas d’éradication de l’incertitude, mais de neutralisation de ceux des effets de l’incertitude radicale qui sont suspensifs des flux. » (Rouvroy, 2015: 115.)
- 11. « Si le pouvoir ne s’exerçait que de façon négative, il serait fragile. S’il est fort c’est qu’il produit des effets positifs au niveau du désir et du savoir. Le pouvoir, loin d’empêcher le savoir, le produit. » (Foucault, 2001: 757.)
- 12. [Je souligne.]
- 13. Cependant, si le contenu visuel ne correspond pas aux descriptions textuelles, Google énonce clairement dans ses « Consignes aux webmasters » qu’il émet des sanctions qui affectent le classement ou entraînent un retrait de l’index.
- 14. Il convient de préciser qu’une image fortement reproduite en ligne augmente ses chances de se retrouver sur des sites déjà bien classés par Google. D’autre part, même si la démonstration reste à faire, il appert aussi que les critères de classement des images semblent souvent plus sensibles à l’effet viral et à l’actualité.
- 15. [Je traduis.]
- 16. [Je traduis.]
- 17. Ces capacités restent délaissées également dans la fonction recherche d’images similaires ou de recherche par images, lesquelles se fondent encore sur une correspondance des pixels plutôt basique.
- 18. [Je traduis.]
- 19. Avec la critique philosophique du langage, on croyait être parvenus à éloigner ce présupposé que « l’être va aussi loin que le langage » (Boehm, 2004).
- 20. « Une définition des big data qui défait un peu le caractère triomphaliste de l’expression big data, c’est tout simplement le passage, d’un seuil de vélocité, de rapidité, de quantité de données, de complexité à partir duquel on ne comprend plus rien avec notre rationalité moderne, c’est-à-dire la rationalité qui consistait à comprendre les phénomènes en les liant à leurs causes. On est obligé de l’abandonner, au profit d’une sorte de rationalité postmoderne purement inductive qui renonce à la recherche des causes des phénomènes et vise tout simplement à plus ou moins prévoir leur survenue. Je caricature un peu, mais c’est le passage d’une logique déductive à une logique purement inductive. » (Rouvroy, 2015 : 116.)
- 21. Dans The Logic of Scientific Discovery (1934) et The Open Universe. An Argument for Indeterminism (1982) par exemple, il critique l’historicisme et sa vocation de prédiction, et prône la réfutabilité contre le vérificationnisme dans la production du savoir.
- 22. Ne serait-ce que par l’incertitude qui subsiste autour des signaux utilisés par Google dans le classement des résultats d’images.
- 23. Bien qu’elle ne soit pas spécifiquement appliquée à caractériser l'univers de l'image, la formule que propose Rouvroy nous paraît mériter d’être citée en entier :« Tous les événements qui peuvent se produire et qu’on ne peut pas prévoir, c’est l’excès du possible sur le probable, c’est-à-dire tout ce qui échappe, par exemple, à la réalité actuarielle à travers laquelle on essaie précisément de rendre le monde gérable en le réduisant à ce qui est prévisible. » (Rouvroy, 2015: 117.)


